(GER) Was sind Diffusion Models

Was hinter dem Hype steckt
(Die deutsche Version beginn unten!)
This post is a rather unusual one since it is in German. I have always been involved in making content available in other languages to allow more people to enjoy it, such as when I did translations for Khan Academy. After translating the posts on normalising flows by Eric Jang, I have the pleasure of now translating Lily Wang’s excellent post on diffusion models. I hope you enjoy it!
- Einführung
- Was sind Diffusion Models
- Forward Diffusion Process
- Verbindung zu Stochastic Gradient Langevin Dynamics
- Reverse Diffusion Process
- Credits
Einführung
GANs, VAEs und Normalising Flows sind drei Typen von Machine Learning Modellen für generative Zwecke. Alle drei haben sehr erfolgreich hochqualitative Beispiele generiert, aber jede der drei Familien hat eigene Probleme. GANs sind bekannt für instabiles Training und weniger Diversität der produzierten Beispiele durch ihr Training. VAEs basieren auf einem sogenannten “surrogate loss”. Normalising Flows müssen spezielle Architekturen verwenden, um reversible Transformationen zu konstruieren.
Diffusion Models sind von der “non-equilibrium” Thermodynamik inspiriert. Sie definieren eine Markov-Kette von Diffusionsschritten, um den Daten langsam zufälliges Rauschen hinzuzufügen, und lernen dann, den Diffusionsprozess umzukehren, um aus dem Rauschen gewünschte Datenproben zu konstruieren. Im Gegensatz zu VAEs oder Normalising Flows werden Diffusion Models mit einem festen Verfahren erlernt, und die latente Variable hat eine hohe Dimensionalität (dieselbe wie die Originaldaten).
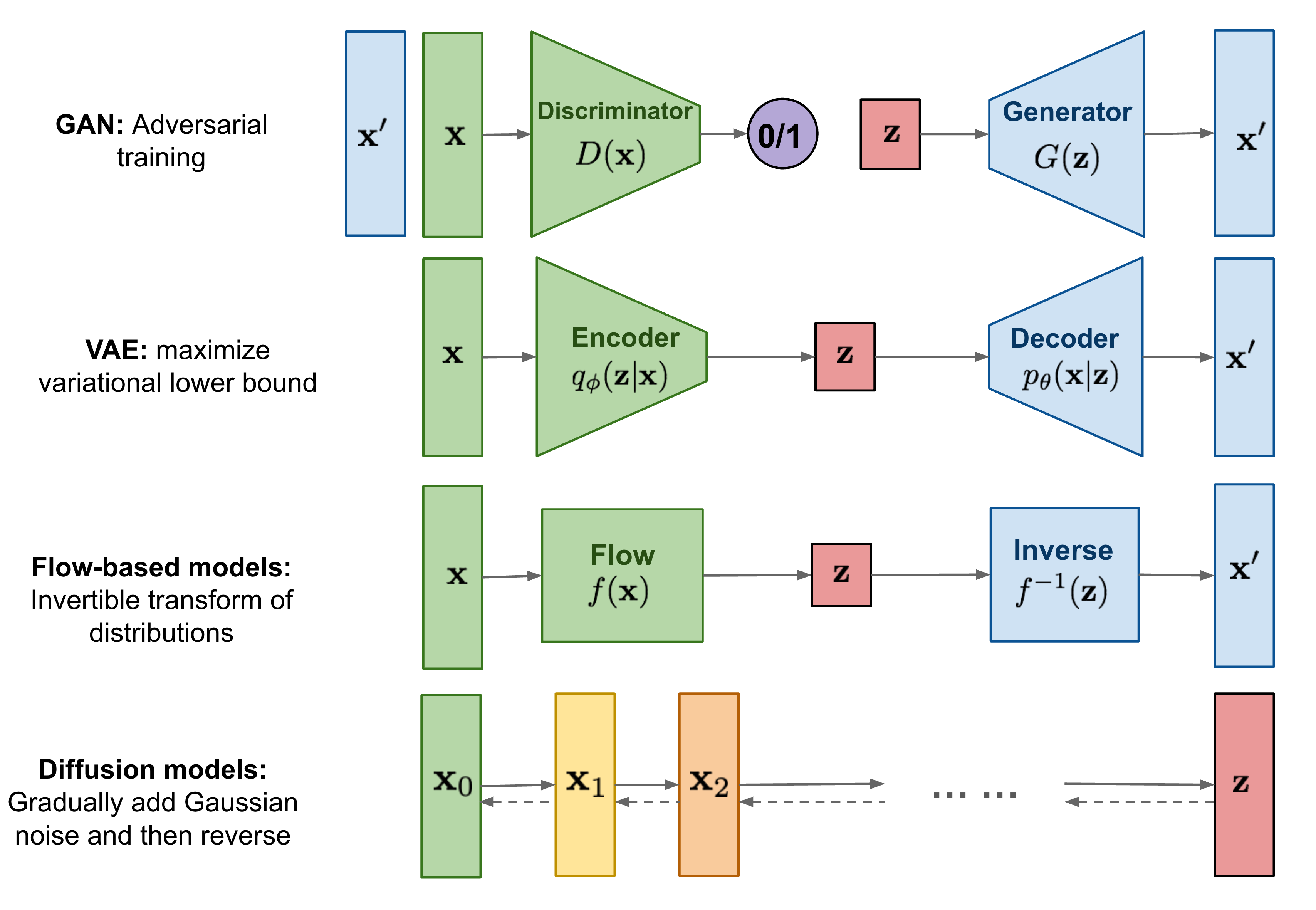
Was sind Diffusion Models
Es wurden mehrere diffusionsbasierte generative Modelle mit ähnlichen Ideen vorgeschlagen, darunter diffusion probabilistic models (Sohl-Dickstein et al., 2015), noise-conditioned score network (NCSN; Yang & Ermon, 2019), und denoising diffusion probabilistic models (DDPM; Ho et al. 2020).
Forward Diffusion Process
Nehmen wir an, wir haben einen Datenpunkt von einer realen Datenverteilung, . Dann können wir einen forward diffusion process definieren, in dem wir in Schritten kleine Mengen an Gaussian noise zu dem Datenpunkt hinzufügen und damit eine Sequenz an korrumpierten (sogenannten noised) Datenpunkten erzeugen. Wir kontrollieren die Schrittgröße zwischen diesen Datenpunkten mit der sogenannten variance schedule .
Unser Datenpunkt verliert so seine erkennbaren Eigenschaften wenn größer wird. Wenn ist equivalent zur isotropen Normalverteilung.
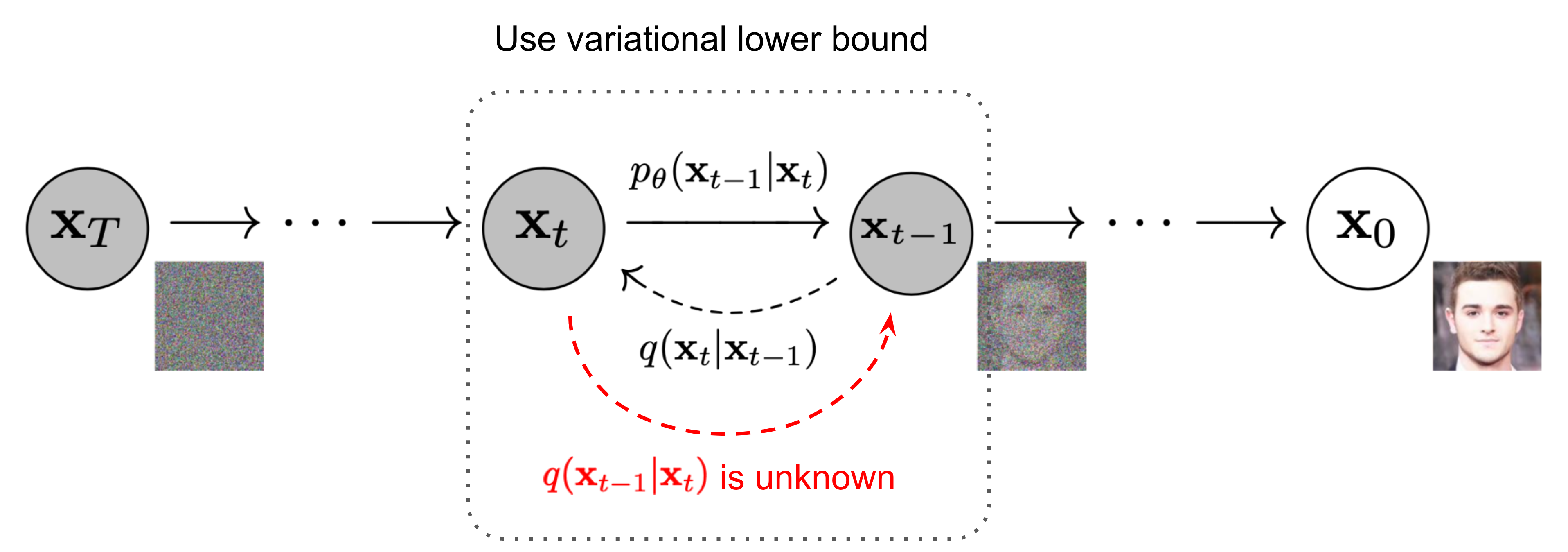
Fig. 2. Die Markovkette des forward (reverse) diffusion process, in dem eine Stichprobe durch langsames Hinzufügen/Entfernen von Rauschen erzeugt wird. Quelle: Ho et al. 2020 mit einigen zusätzlichen Anmerkungen.
Eine nützliche Eigenschaft dieses Prozesses ist dass wir zu einem beliebigen Zeitpunkt in geschlossener Form samplen können, und zwar mithilfe eines Reparametrisierungs-Tricks. Sei und :
(*) Wenn wir zwei Normalverteilungen mit verschiedenen Varianzen kombinieren, hat die neue Normalverteilung die Summe der Varianzen als Varianz: . In unserem Falle ist die kombinierte Standardabweichung .
Normalerweise können wir uns größere Updateschritte erlauben wenn unsere Sample mehr Rauschen enthält, also setzen wir die variance schedule so, dass mit wächst: und daher .
Verbindung zu Stochastic Gradient Langevin Dynamics
Langevin Dynamics ist ein Konzept aus der Physik das zur statistischen Modellierung von molekularen Systemen entwickelt wurde. Wenn dieses Verfahren mit stochastic gradient descent kombiniert wird, erhalten wir stochastic gradient langevin dynamics (Welling & Teh 2011). Dieses Verfahren kann Stichproben von einer Wahrscheinlichkeitsverteilung ziehen und benötigt hierfür nur die Gradienten der Log-Wahrscheinlichkeit . Die Gradienten werden mit einem Rauschterm kombiniert, um die Stichproben zu erzeugen. Die Stichproben werden dann verwendet, um die Gradienten zu schätzen, und der Prozess wird wiederholt. Dieser iterative Prozess kann als Markovkette bestehend aus Updates beschrieben werden:
mit als die Schrittgröße der Updates. Wenn wir gehen lassen, geht und wir erhalten die tatsächliche Wahrscheinlichkeitsverteilung .
Verglichen mit standard Gradient Descent Methoden, die nur die Gradienten der Log-Wahrscheinlichkeit verwenden, fügen wir hier einen Rauschterm hinzu. Hierdurch verhindern wir den Kollaps in lokale Minima der Wahrscheinlichkeitsverteilung.
Reverse Diffusion Process
Wenn wir den oben beschriebenen forward diffusion process umkehren und somit Stichproben von ziehen könnten, können wir aus Gauss’schen Rauschen Stichproben von ziehen. Dieser Prozess wird als reverse diffusion process bezeichnet.
Falls klein genoug ist, wird ebenfalls einer Normalverteilung folgen.
Leider müssten wir die gesamte Datenverteilung kennen, um zu berechnen. Dies ist in der Praxis nicht möglich. Wir können jedoch ein Modell lernen, dass diese bedingten Wahrscheinlichkeiten approximiert. Mithilfe dieses Modells können wir dann den reverse diffusion process durchführen und näherungsweise Stichproben von ziehen:
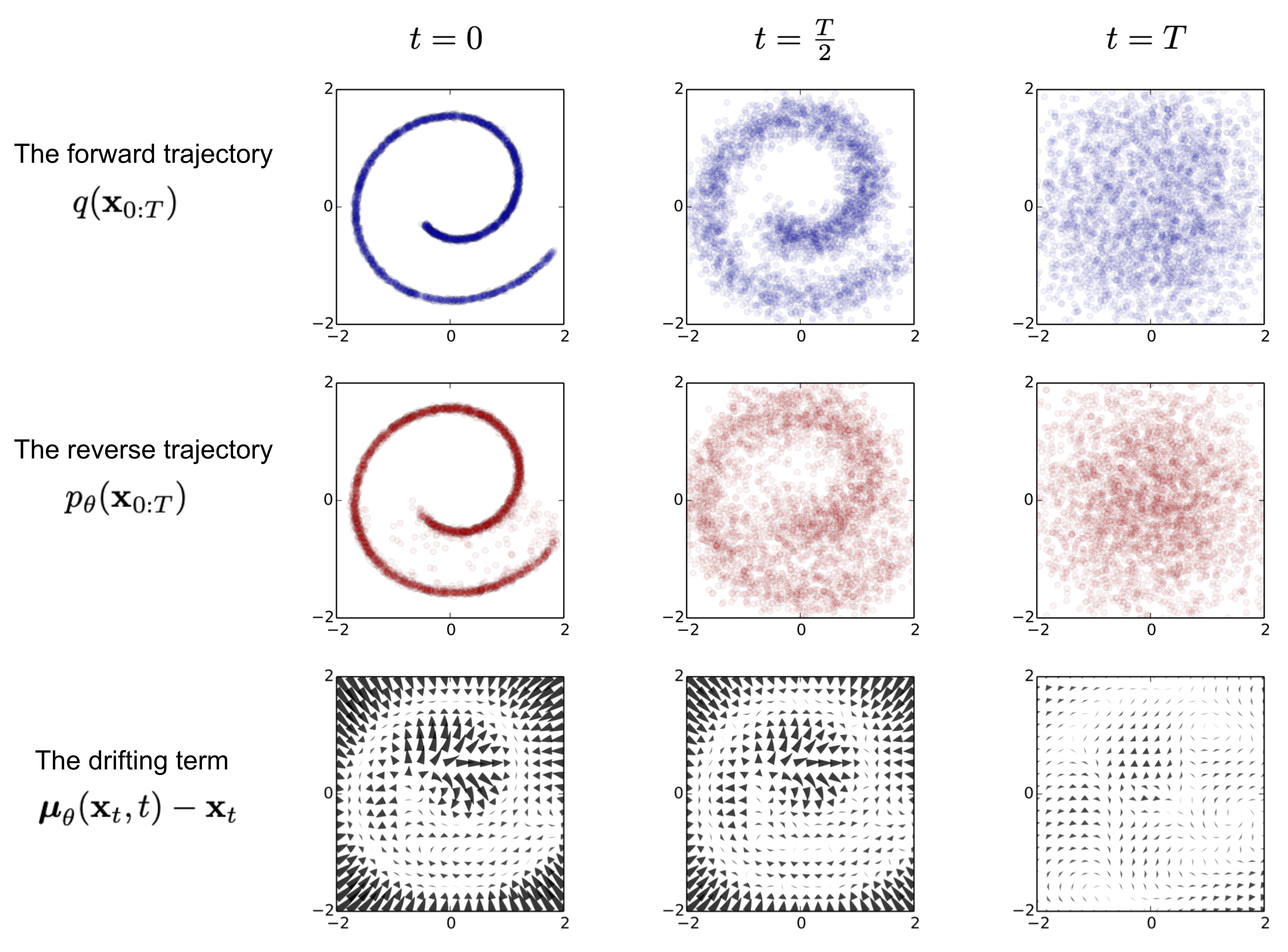
Fig. 3. Beispielhaftes Training eines Diffusion Models zum Modellieren von 2D swiss roll daten. (Quelle: Sohl-Dickstein et al. 2015)
Es ist bemerkenswert dass die reverse bedingte Wahrscheinlichkeit berechnet werden kan, wenn diese auf bedingt ist:
Mit dem Satz von Bayes erhalten wir folgendes:
Credits
Vielen Dank an Lilian Weng für ihre coolen Blogposts und die Möglichkeit, diesen Blogpost zu übersetzen!
